Build High-Performing Application Platforms, Expertly Crafted.
I simplify Kubernetes and create self-serviced Cloud Native platforms for developers.
See My Services





Cloud Native Technology Applied
Addressing software delivery and platform management challenges with the most innovative solutions.
View Solutions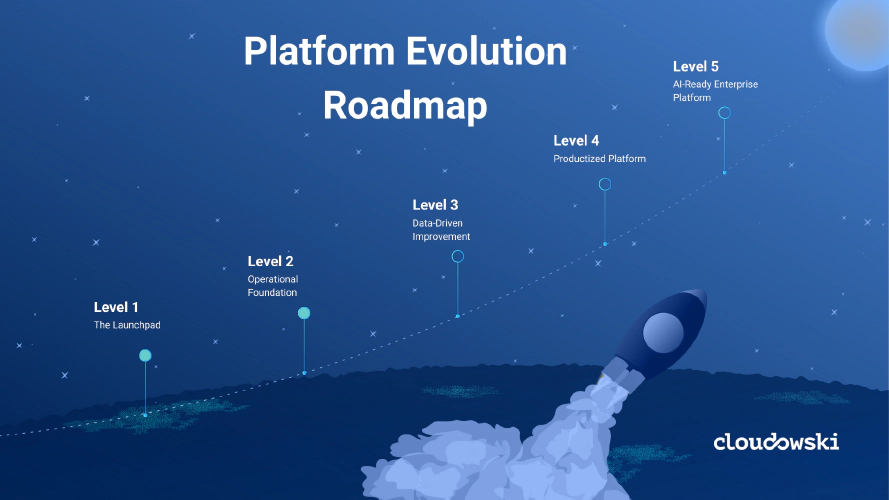




Expertise. Passion. Empathy.
I'm an Independent Consultant & Platform Architect.

The technology is already here. All that remains is to apply it appropriately, taking into account the context, constraints and goals of the organization. I can help you with that.
Proven Skills
I use my natural passion for learning and problem-solving in every project, which in turn has pushed me towards certification and I have been able to earn many industry-recognized certifications.
Validated Technology
I specialise in the area of DevOps and Platform Engineering. I use Kubernetes and other Cloud Native technologies to help my clients build reliable application platforms maintained entirely from code (GitOps/Everything As Code).
See My Services
What My Clients Said
Why Work With Me?

“Tomasz has played a crucial role in revolutionizing our software delivery processes by implementing cutting-edge technologies like containers, Kubernetes, and Red Hat OpenShift Container Platform.”
Jarosław MajHead of CRM & Digital System Development, P4

“His insights and expertise on the subject were very helpful in understanding even the most complex of the inner workings of Kubernetes and Cloud Native projects.”
Robert BrytanDirector of Data Center, Asseco Business Solutions

Student Review
“Twój kurs Kubernetesa wciągnął mnie całkowicie! Właśnie zaczynam przerabiać dziesiąty moduł z wersji PRO. I dzięki Tobie naprawdę czuję, że coś wiem na temat Kubernetesa! Dlatego naprawdę z całego serca chciałbym Tobie podziękować za to jak wiele mnie nauczyłeś! Dodam, że bardzo dobrze się Ciebie słucha! Twój kurs słucham tak naprawdę drugi raz. Za pierwszym razem po prostu w całości jednym ciągiem przesłuchałem wersje fundamenty i pro, bez jakiejkolwiek przerwy. A obecnie słucham drugi raz, i tym razem staram się robić notatki w formie fiszek. Bardzo mi to pomaga w nauce. I mimo, że słucham materiału, który już wcześniej przesłuchałem to naprawdę nie jestem znudzony i cały czas materiał sprawia mi wiele radości i czystej fascynacji. Także proszę nie przestawaj nauczać! 🙂”
Mariusz GałązkaIT Specialist
“It is our pleasure to recommend Tomasz Cholewa as a professional trainer providing high standard services for the benefit of their clients.”
Robert BrytanDirector of Data Center, Asseco Business Solutions

Student Review
“Jest to pierwszy kurs wideo, na który się zdecydowałem i dzięki temu, że lekcje były konkretne i treściwe to byłem w stanie się skoncentrować i przerobić materiały do końca. Wiele przydatnych informacji znalazłem w module PRO, który nakreślił mi best practices odnośnie uruchamiania aplikacji produkcyjne oraz wskazał na co uważać. Teoria jest bardzo ważna, ale praktyka jeszcze ważniejsza i tak było w moim przypadku, gdy laby z kursu pomogły mi jeszcze lepiej przyswoić wiedzę.”
Manuel SaksDevOps Engineer

Student Review
“Tomek zrobił kawał porządnej roboty: w jednym miejscu znajdziesz wszystko czego potrzeba do okiełznania Kubernetesa.Polecam ten kurs wszystkim!”
Irek SobkowiczDevOps Engineer