

UPDATED on 10.6.2019 (after the release of OpenShift 4.1): Added information on OpenShift 4.
UPDATED on 30.8.2019: Added information on CodeReady Containers for running single OpenShift node.
OpenShift has been often called as “Enterprise Kubernetes” by its vendor – Red Hat. In this article, I’m describing real differences between OpenShift and Kubernetes.
It’s often confusing, as Red Hat tends to describe it as PaaS, sometimes hiding the fact that Kubernetes is an integral part of OpenShift with more features built around it. Let’s dive in and check what are the real differences between those two.1. OpenShift product vs. Kubernetes project
Kubernetes is an open source project (or even a framework), while OpenShift is a product that comes in many variants. There’s an open source version of OpenShift which is called OKD. Previously it was called OpenShift Origin, but some “clever” folks at Red Hat came up with this new name which supposes to mean “The Origin Community Distribution of Kubernetes that powers Red Hat OpenShift” (?). But let’s forget about names for a while and focus on what are implications of that.
There are a couple of them:
- OpenShift Container Platform is a product that you can install on your infrastructure that has a paid support included that comes with a subscription
- You need to renew your OpenShift subscription for your cluster and you pay more when your cluster grows
- Kubernetes has many distributions, but it’s a project and if something bad happens you can count mostly on community or external experts (in some cases they might be sometimes better than Red Hat support 🙂 )
- Kubernetes has many releases per year (4 actually), OpenShift has also many releases, but it falls behind Kubernetes release schedule – version 3 at the time of writing was far behind (it includes Kubernetes 1.11 while the newest release was 1.14) while version 4 was “only” one release behind and should follow upstream Kubernetes in the future releases
- As a product OpenShift subscription includes CloudForms (only in version 3) that enhance it with its features (e.g. configurable chargeback, monitoring, central provisioning etc.)
- OKD version is free to use and includes most of the features of its commercial product, but you cannot buy a support nor you cannot use Red Hat based official images
So if you need a support for Kubernetes one option would be to buy subscription for OpenShift. If you’re okay with self-support then of course there’s Kubernetes with plenty of side projects, whole ecosystem and fantastic community. For hesitant ones there’s a OKD project with almost all OpenShift features – you can later might decide to migrate to a commercial product or stick with OKD.
Which is better?
It depends on whether you’d rather pay and use support and all the features that come with a product (OpenShift) rather than project (Kubernetes, but also OKD) with self-support model.
2. OpenShift limited installation vs. install Kubernetes (almost) anywhere
If you decide to install OpenShift you need to use either
- Red Hat Enterprise Linux (RHEL) or Red Hat Atomic on OpenShift 3
- Red Hat CoreOS (required by control plane – master and infra server, default for compute nodes) and optionally RHEL for compute nodes only on OpenShift 4
- RHEL or CentOS for OKD.
You cannot install it on other linux distributions. Kubernetes, on the other hand, can be installed almost on any linux distribution such as Debian, Ubuntu (most popular ones) and many others.
When it comes to installation when choosing OpenShift you can install it on multiple platforms depending on the version:
- OpenShift 3 – manually following reference guides (yes, you need to install it using ssh, yum, vim and other old-school tools) or with openshift-ansible project. The latter is probably a better choice, but since it needs to be universal and it’s written in Ansible it’s a little bit slow, complex and hard to troubleshoot. It does come with a major feature coveted by enterprise environments – rolling-update of the whole cluster. This is a major advantage and you will probably appreciate it when you decide to upgrade your Kubernetes cluster.
- OpenShift 4 – has a simplified and easier to use installer that currently supports AWS and vSphere. It is performed by a dedicated Operator software and the whole configuration is kept in ConfigMaps inside a cluster (not in files on master servers like in version 3). Bare metal installations are still possible but currently they require many manual steps. Also it requires internet connections so disconnected installations are unavailable.
Kubernetes on the other hand has many installation tools available (e.g. kubeadm, kube-spray, kops), some of them are better for cloud, some are more universal and complex too and it’s up to you to decide how you want to install your cluster and upgrade it (if it’s supported by the tool).
The last thing regarding freedom of choice for your platform are services available on major cloud platforms. Kubernetes is available on three of them – GKE on Google GCP, EKS on Amazon AWS anf AKS on Microsoft Azure.
For OpenShift there’s a product called OpenShift Online, OpenShift Dedicatedand OpenShift on Azure. Additionally you can test your single node installations using the following methods:
- Minikube for Kubernetes
- Minishift for OKD (formerly OpenShift Origin)
- CDK for OpenShift Container Platform 3
- CRC (CodeReady Containers) for OpenShift Container Platform 4
Which is better?
Kubernetes has become a standard and is available on more platforms than OpenShift. However, with the new, more flexible and faster installer we can expect that OpenShift will be a good alternative for Kubernetes, also in the cloud.
3. OpenShift has more strict security policies than default Kubernetes
It’s probably because of the target group for OpenShift product, but indeed default policies are more strict there than on Kubernetes. For example, most of container images available on Docker Hub won’t run on OpenShift, as it forbids to run a container as root and even many of official images don’t meet this requirement. That’s why people are sometimes confused and angry because they cannot run simple apps like they used to on Kubernetes. There’s an easy way to disable that policy, but still it shows a different approach to security.
Also, RBAC was an integral part of OpenShift since many releases while there are some people who use Kubernetes without RBAC security. That’s okay for a small dev/test setup, but in real life, you want to have some level of permissions – even if it’s sometimes hard to learn and comprehend (because it is at first). In OpenShift you actually don’t have a choice and you have to use it and learn it on the way as you deploy more and more apps on it.
Last part is authentication and authorization model. There are additional mechanisms in OpenShift that makes integration with Active Directory easy, but more interesting part is authorization to external apps. As a part of OpenShift you can install additional component such as
- Internal Container Registry
- Logging stack based on EFK (ElasticSearch, Fluentd, Kibana)
- Monitoring based on Prometheus
- Jenkins
and you use a single account to authenticate to them with OAuth mechanism (oauth-proxies running as sidecars). That makes permissions management easier and can bring additional features like in EFK where you see logs only from namespaces/projects you have access to. And yes – you can achieve the same on Kubernetes as well, but it requires a lot of work.
Which is better?
Definitely “secure by default” approach in OpenShift.
4. OpenShift templates are less flexible than Kubernetes Helm charts
For someone coming straight from Kubernetes world who used Helm and its charts, OpenShift templates as the main method of deployment whole stack of resources is just too simple. Helm charts use sophisticated templates and package versioning that OpenShift templates are missing. It makes deployment harder on OpenShift and in most cases you need some external wrappers (like I do) to make it more flexible and useful in more complex scenarios than just simple, one pod application deployments. Helm is so much better, but its current architecture (Tiller component installed as Pod with huge permissions) isn’t compatible with more strict security polices in OpenShift.
There are some other options available in OpenShift 3 such as Automation Broker (formerly Ansible Service Broker) or Service Catalog, but they can be installed on Kubernetes while Helm is not a (supported) option on OpenShift. Hopefully, it will change in future with version 3 of Helm where there will be no Tiller component that makes it hard to make secure. Until then when working on OpenShift you need to live somehow with those inflexible templates looking with envy on those fancy Helm charts.
OpenShift 4 has an integrated OperatorHub which is becoming the preferred way for provisioning services (i.e. databases, queue systems). It will become eventually the best way to deploy services on OpenShift (and Kubernetes too).
Which is better?
Kubernetes Helm is more flexible and upcoming version 3 will make it more secure and applicable in more serious projects. However, with more operators available on OperatorHub, OpenShift 4 will gain an advantage.
5. Routers on OpenShift vs. Ingress on Kubernetes
Red Hat had needed an automated reverse proxy solution for containers running on OpenShift long before Kubernetes came up with Ingress. So now in OpenShift we have a Route objects which do almost the same job as Ingress in Kubernetes. The main difference is that routes are implemented by good, old HAproxy that can be replaced by commercial solution based on F5 BIG-IP. On Kubernetes, however, you have much more choice, as Ingress is an interface implemented by multiple servers starting from most popular nginx, traefik, AWS ELB/ALB, GCE, Kong and others including HAproxy as well.
So which one is better you may ask? Personally, I think HAproxy in OpenShift is much more mature, although doesn’t have as much features as some Ingress implementations. On Kubernetes however you can use different enhancements – my favorite one is an integration with cert-manager that allows you to automate management of SSL certificates. No more manual actions for issuing and renewal of certificates and additionally you can use trusted CA for free thanks to integration with Letsencrypt!
As an interesting fact, I want to mention that starting from OpenShift 3.10 Kubernetes Ingress objects are recognized by OpenShift and are translated/implemented by.. a router. It’s a big step towards compatibility with configuration prepared for Kubernetes that now can be launched on OpenShift without any modifications.
Which is better?
Both are great, Ingress is newer and less mature than Router, but they do a great job.
6. A different approach to deployments
Similarly like with Ingress, OpenShift chose to have a different way of managing deployments. In Kubernetes there are Deployment objects (you can also use them in OpenShift with all other Kubernetes objects as well) responsible for updating pods in a rolling update fashion and is implemented internally in controllers. OpenShift has a similar object called DeploymentConfig implemented not by controllers, but rather by sophisticated logic based on dedicated pods controlling whole process. It has some drawbacks, but also one significant advantage over Kubernetes Deployment – you can use hooks to prepare your environment for an update – e.g. by changing database schema. It’s a nifty feature that is hard to implement with Deployment (and no, InitContainers are not the same, as it’s hard to coordinate it with many instances running).
Deployment, however, is better when dealing with multiple, concurrent updates – DeploymentConfig doesn’t support concurrent updates at all and in Kubernetes you can have many of them and it will manage to scale them properly.
Which is better?
OpenShift DeploymentConfig has more options and support ImageStream so I’m choosing it over classic Kubernetes Deployment.
7. Better management of container images
Now this is something that I really miss in Kubernetes and personally my favourite feature of OpenShift. ImageStreams for managing container images. Do you know how “easy” it is to change a tag for an image in a container registry? Without external tools such as skopeo you need to download the whole image, change it locally and push it back. Also promoting applications by changing container tags and updating Deployment object definition is not a pleasant way to do it.
That’s why I love ImageStreams and here are main reasons and features:
- with ImageStream you upload a container image once and then you manage it’s virtual tags internally in OpenShift – in one project you would always use devel tag and only change reference to it internally, on prod you would use stable or prod tag and also manage it internally in OpenShift, not dealing with registry!
- when using ImageStream with DeploymentConfig you can set a trigger which starts deployment when a new image appears or tag changes its reference – it’s perfect for development environments where app deploys itself whenever a new version is built (without any CICD process!)
- with triggers you can achieve even more – having chained builds to create an updated version of your app/tool whenever a new version of the base image is published – it’s an automated patching of all container images built from insecure images at hand!
- you can hide the origin of the image by exposing it as an ImageStream – e.g. one time jenkins points to a original, official image and when you wish to change something, you build your own, push it into your registry and change only reference in ImageStream, not in deployment configs like you would with traditional docker images
If you’re interested in more details you might want to check my article.
Which is better?
ImageStreams in OpenShift are awesome!
8. Integrated CI/CD with Jenkins
Red Hat created OpenShift long before Kubernetes project was found and from the start, it was a PaaS platform. By switching from their custom solution (they used something they called gears instead of containers) to Kubernetes it became easier to bring more features and one of the most exciting is integrated Jenkins. There are multiple CI/CD software solutions available, but Jenkins is still the biggest, most universal, generic and mature solution. It is also often used with Kubernetes clusters to build container images, perform Continuous Integration tasks on them and deploy them as containers on multiple environments with Continuous Deployment pipelines.
Since it’s so popular then having it as a builtin part of OpenShift makes the whole CI/CD a lot less painful. Here’s a list of my favorite features of integrated Jenkins on OpenShift:
- OAuth authentication – use your OpenShift login to log in to Jenkins and depending on the role you have on the project you get one of three jenkins role assigned (view, edit or admin). In OpenShift 4 it finally works as a Single-Sign-On (in version 3 you have to login to a service each time using the same credentials).
- support for source-to-image that allows you to create a custom jenkins image – a few files with plugins list, custom configuration and other resources, enable you to easily update it when a source image changes (that part also can be automated!) and use Jekins in a fully “immutable” mode
- two versions of template available – ephemeral for testing purposes and persistent with persistent storage for more serious job, configuration data and job history is kept separately from Jenkins itself and thus making it very easy to manage (e.g. upgrades, testing different sets of plugins)
- synchronization of secret object from a namespace it’s running on – different secrets are synchronized with Jenkins credentials so that username/password, ssh key or secret text are available in your jobs without ever creating them in Jenkins
- last but not least – pipeline definition is a separate BuildConfig object and is also defined outside of Jenkins as a OpenShift object from simple yaml file
Which is better?
Once again an additional feature of OpenShift makes it easy to deploy your apps with CI/CD pipelines.
9. OpenShift projects are more than Kubernetes namespaces
This a minor difference, but on OpenShift there are projects which are nothing more than just Kubernetes namespaces with additional features. Besides trivial things such as description and display name (trust me – they can be helpful when you have dozens of them), projects add some default objects. Currently a few roles (RoleBinding objects to be precise) are created alongside with a project, but you can modify default project template and use it to provision other objects. A good example would be network policies that close your project for external traffic so that is isolated and secure by default – if you want to permit some kind of traffic you would do so by creating additional policies explicitly. In a similar way you could provide default quotas or LimitRange objects and make your new projects pre-configured according to your organization rules.
Which is better?
Actually projects are namespaces with few features. There’s no clear winner here.
10. OpenShift is easier for beginners
As the last part I want to emphasise the difference when it comes to user experience. Containers are still new and having a complex, sophisticated interface for managing them makes it even harder to learn and adapt. That’s why I find OpenShift versions of both command line and web interfaces superior over Kubernetes ones.
Let’s start with cli. On OpenShift there’s a oc command which is equivalent of Kubernetes’ kubectl with the following differences:
ochas support for logging to OpenShift cluster – with kubectl you need to obtain your credentials and create yourkubeconfigfile with some external toolsoclets you switch between projects/namespaces whilekubectldoesn’t (you need exernal tools such as kubens/kubectx) – if you start working with many namespaces and clusters you will appreciate that feature, believe meocallows you to build a container image from a source and then deploy it onto environments with a single command! (oc new-app) It will create all required objects for you and then you may decide to export them, change and reapply or store somewhere in your repository
Let’s face it – if you’re beginner then you won’t touch command line at first – you’d probably choose to play with some web interface. And after you saw this
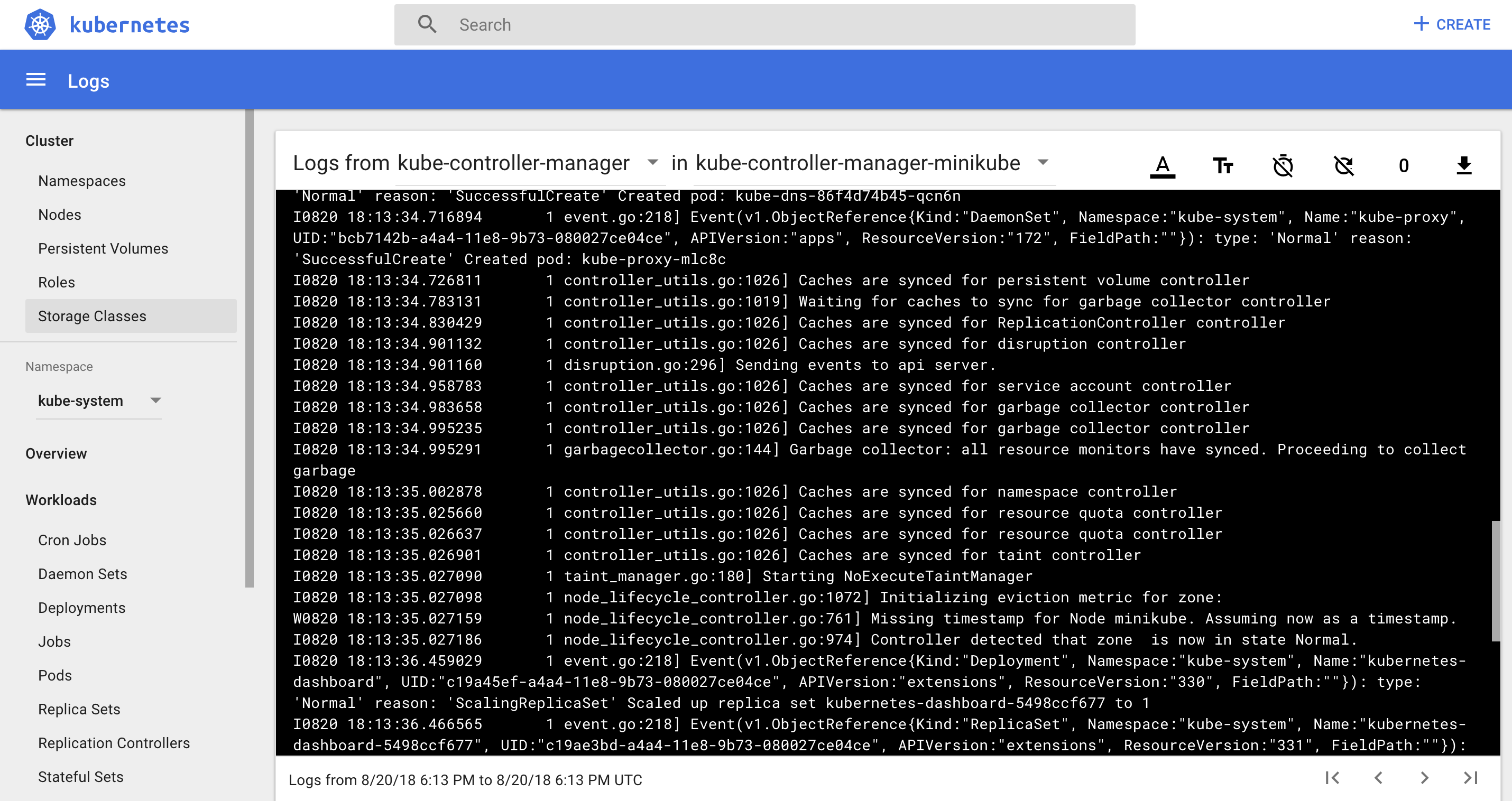
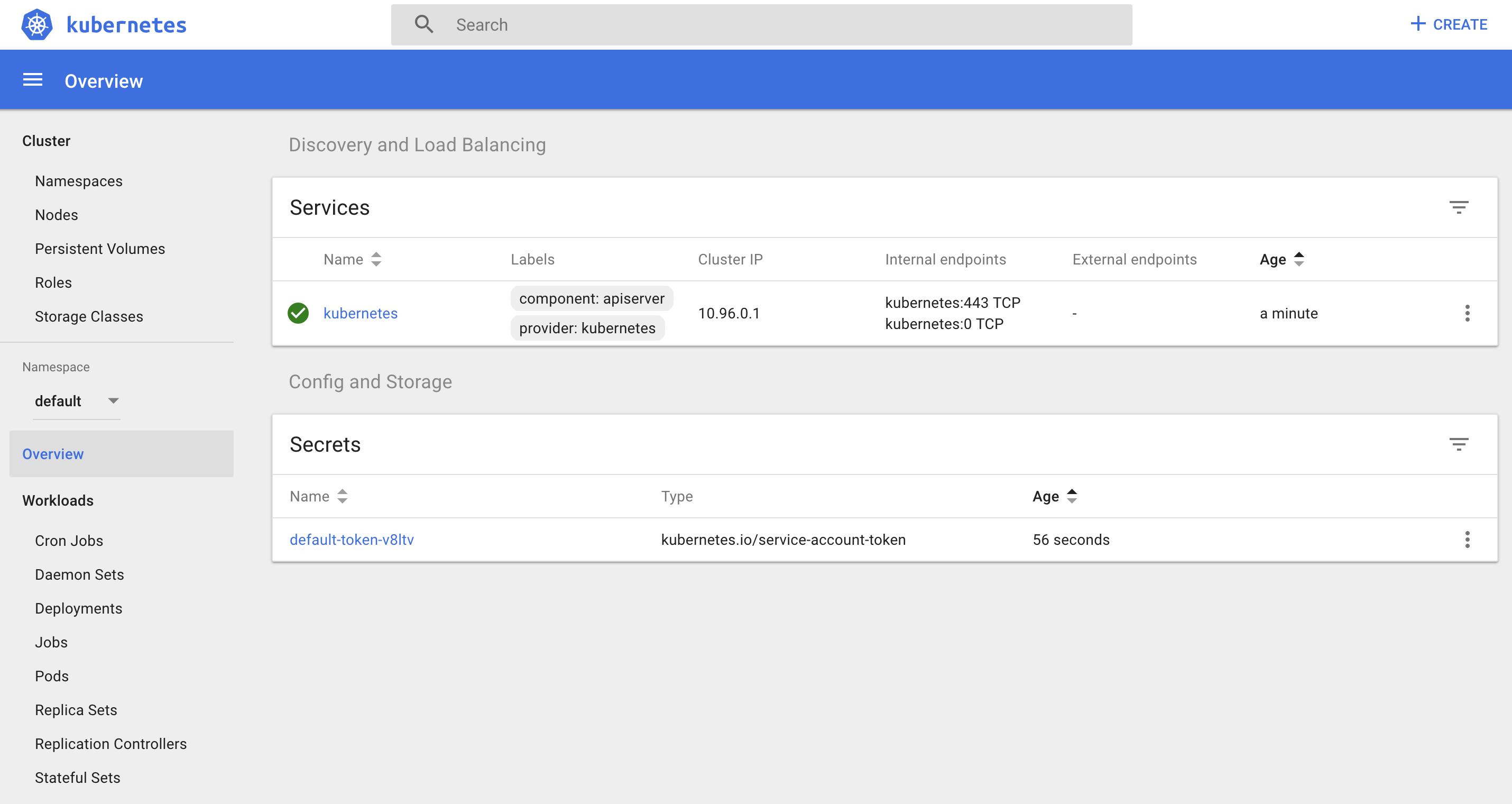
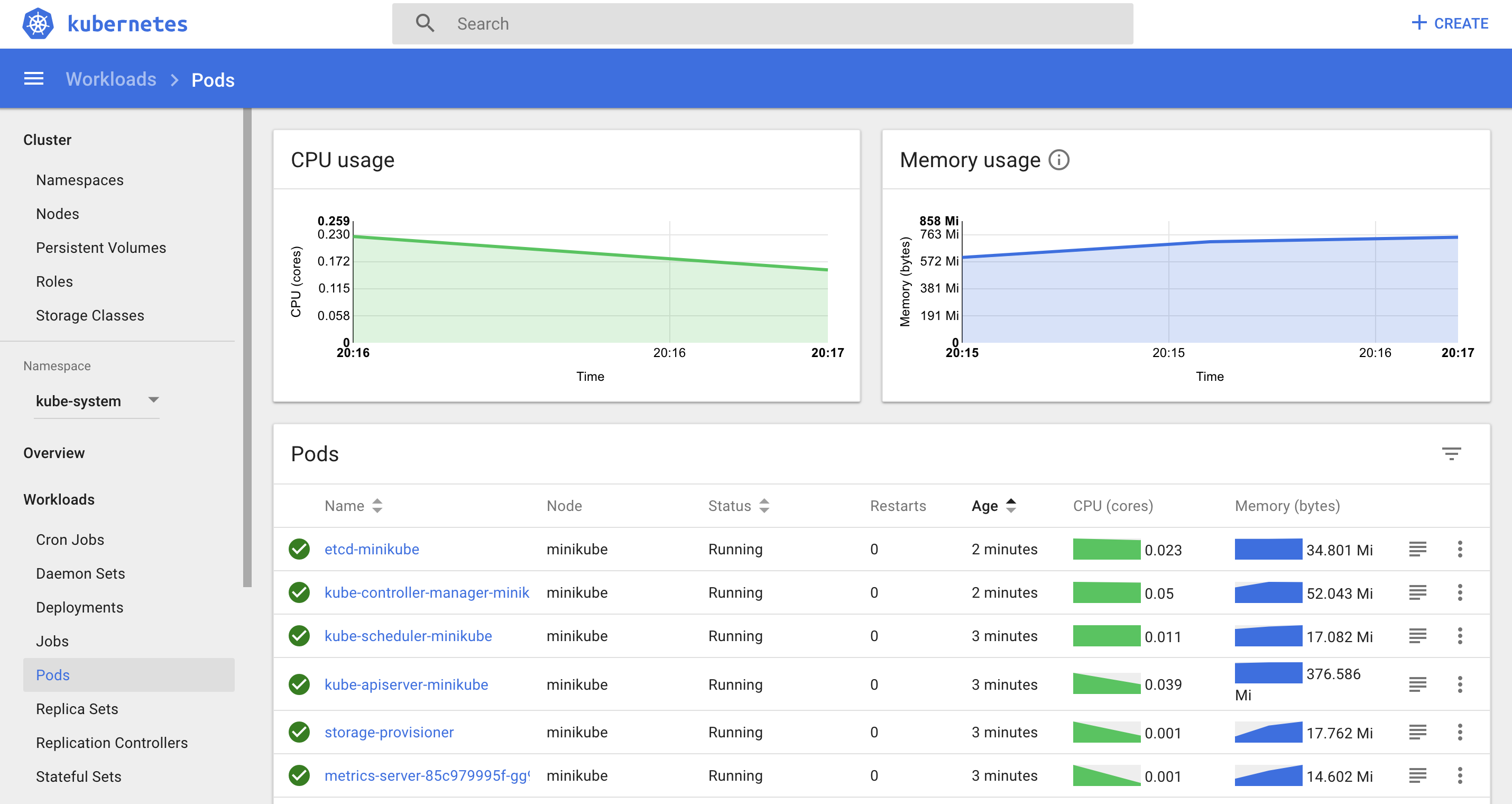
you would probably be discouraged as I did when I saw it for the first time (it was a couple of years ago, but it hasn’t changed a lot unfortunately). It can be overwhelming and personally I don’t use dashboard when working with Kubernetes, as it doesn’t bring much more information than command line and you are not able to change most of the things – it’s almost like read-only panel. Let’s face it – dashboard is not a first-class citizen among many Kubernetes projects.
Now here’s the OpenShift 3 web console:
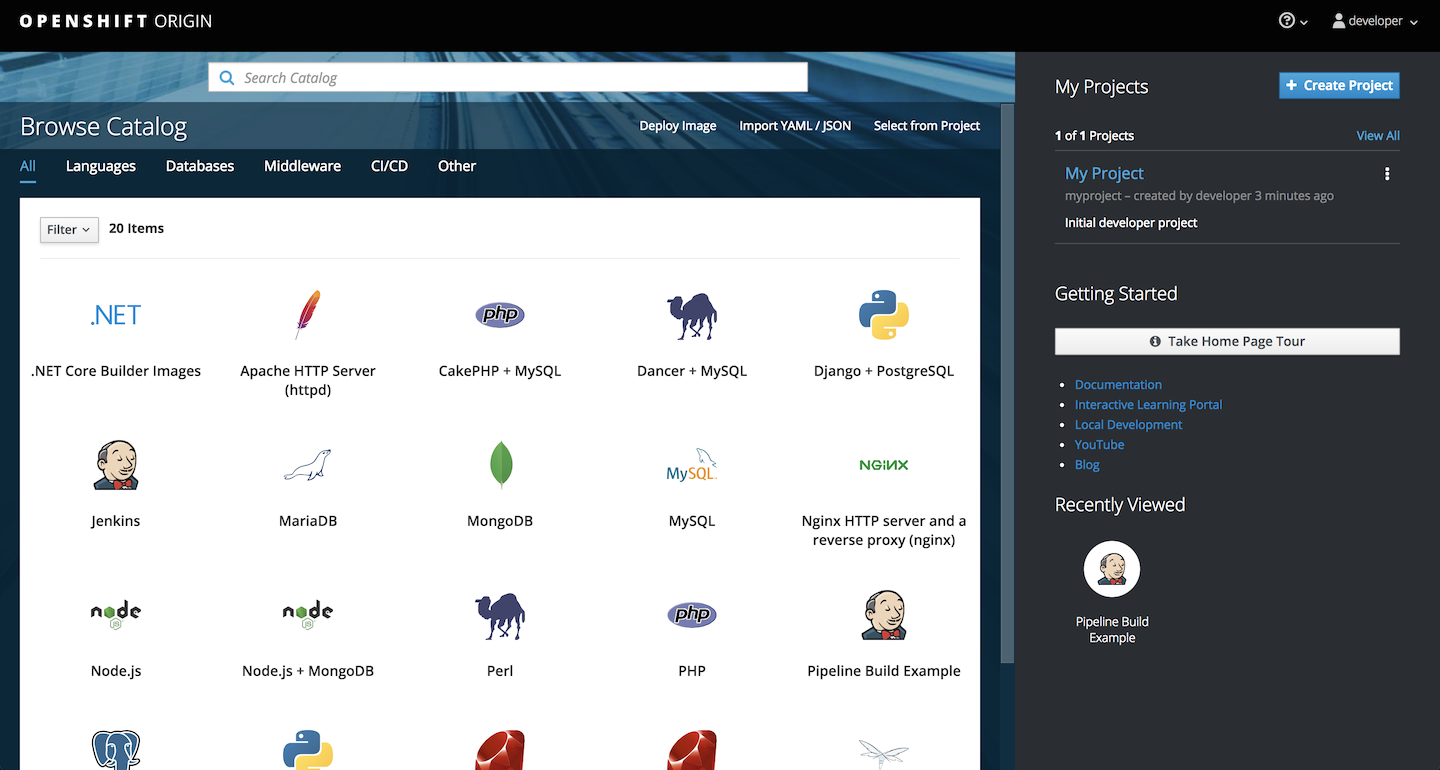
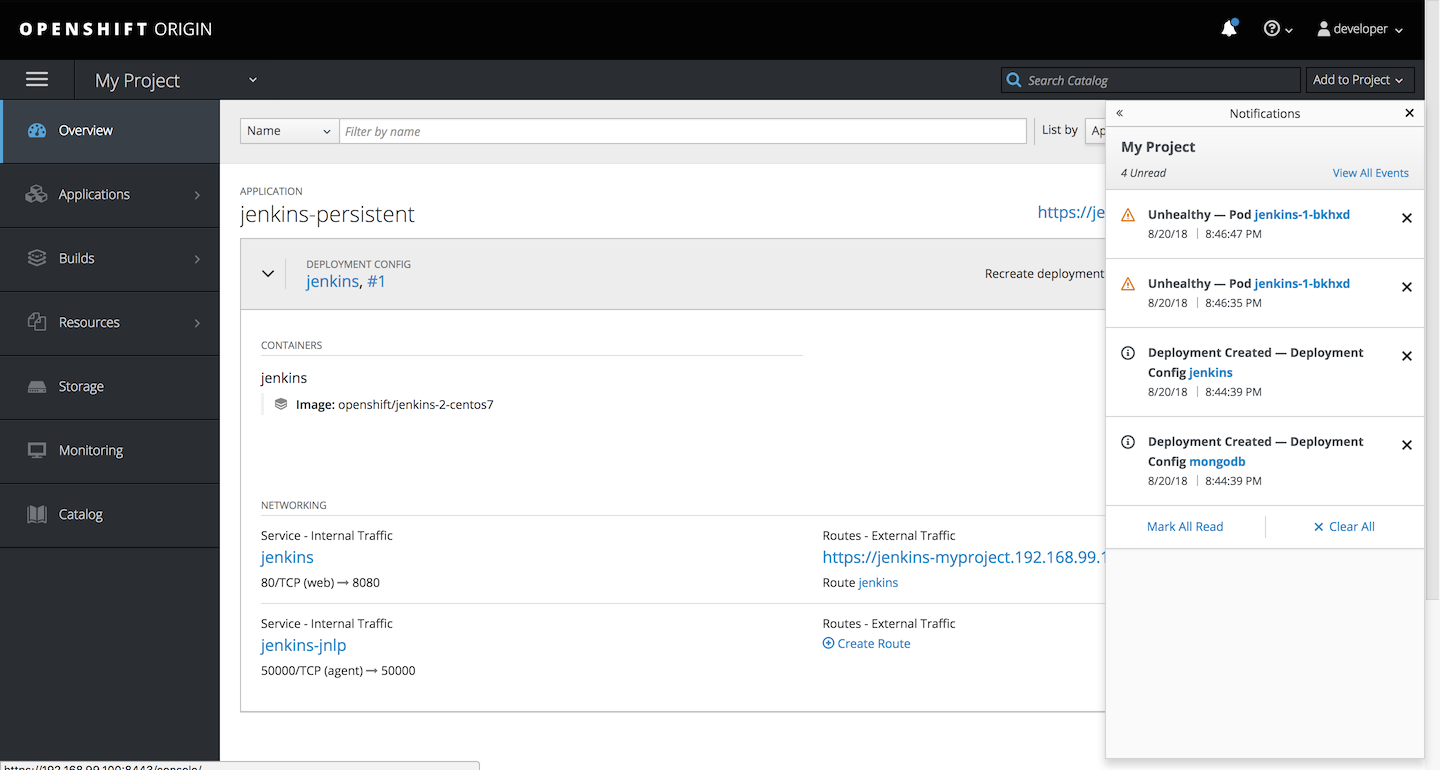
And the redesigned version available in OpenShift 4:

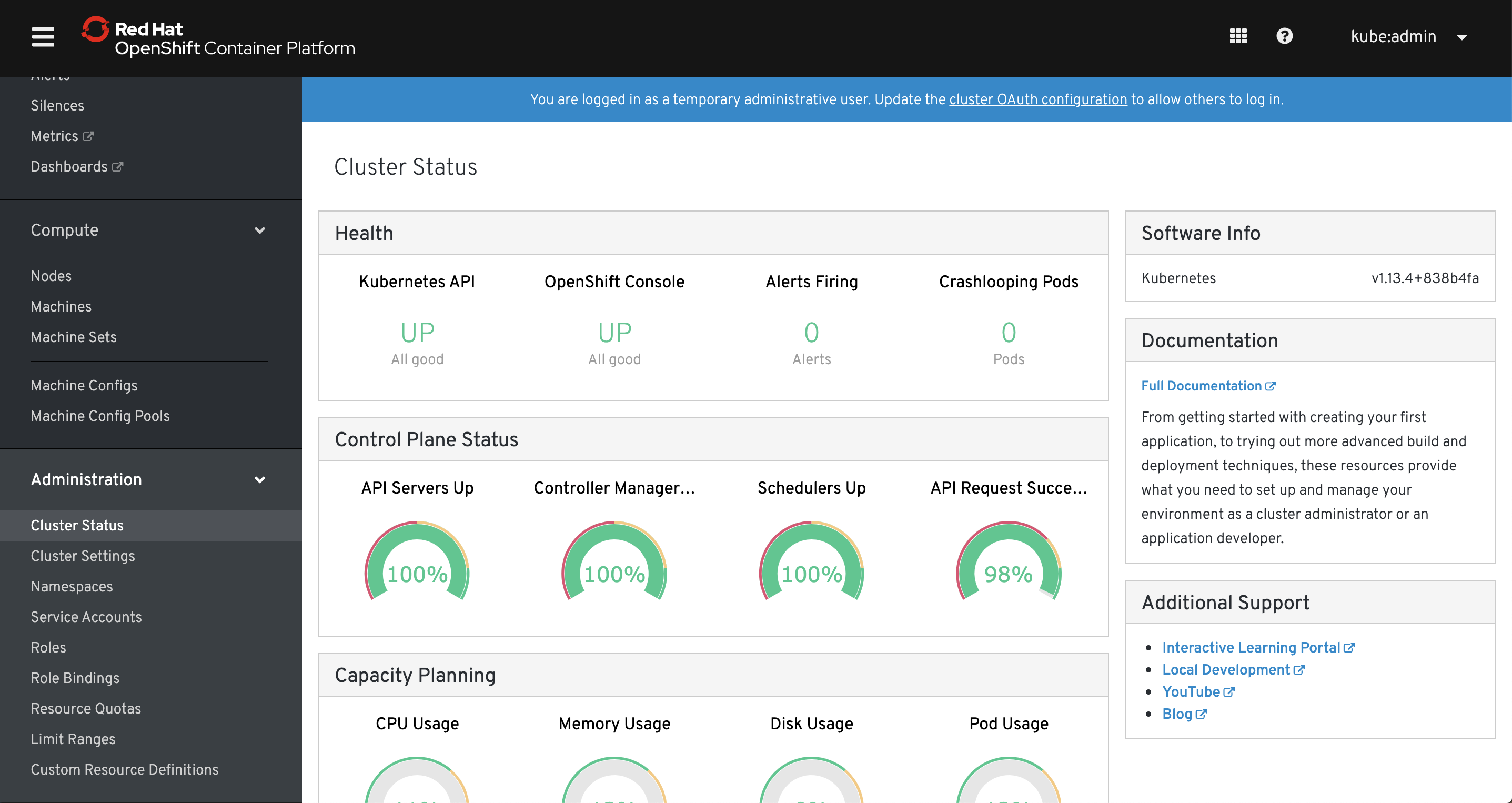
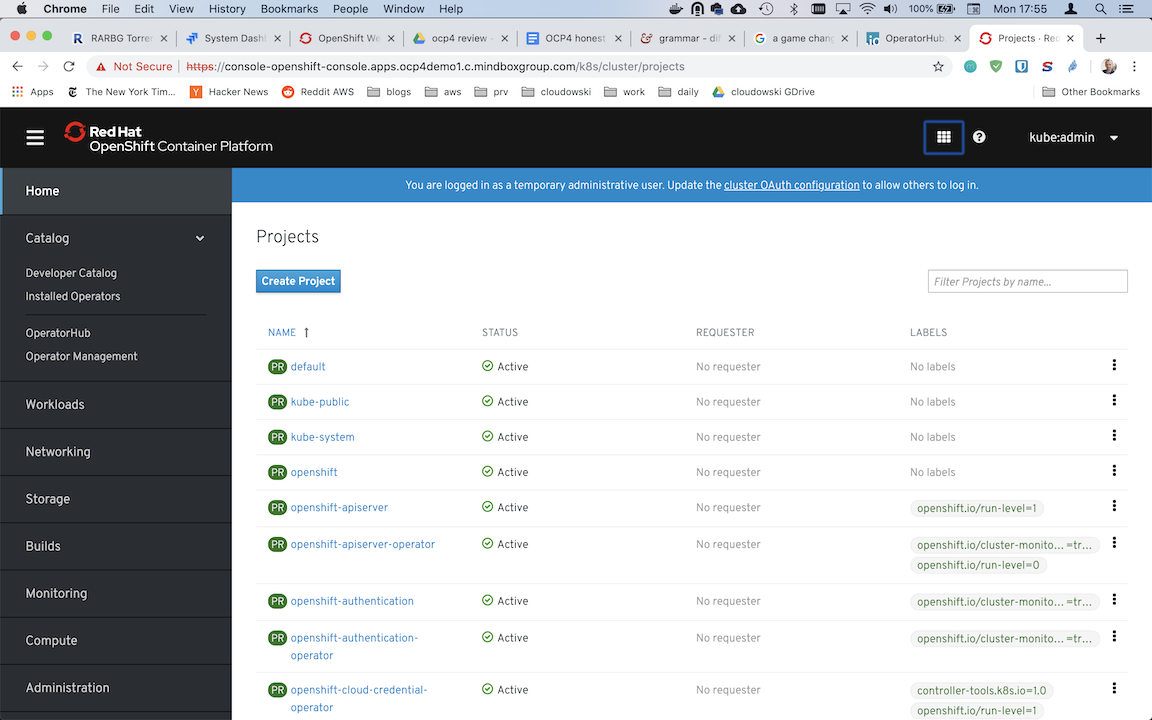
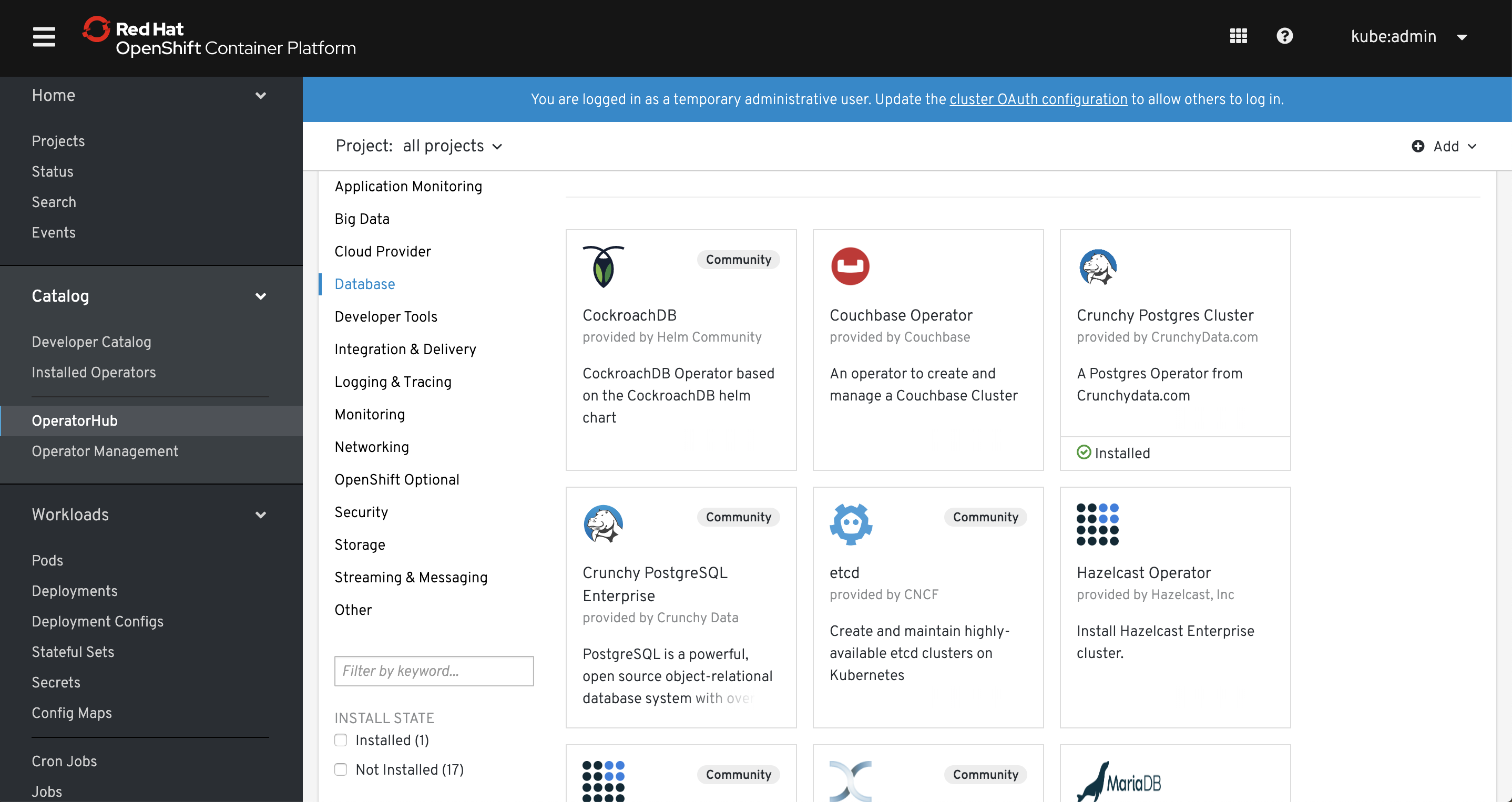
Now I’m not saying it’s the best web interface, but I consider it as one of the best features of OpenShift. First of all it has a login window, something that simple and trivial and I know it shouldn’t be a feature, but have you seen Kubernetes “login window”? Dashboard has a login window where you provide a token and honestly is confusing, especially for beginners.
Most of all OpenShift web console is very useful, much more than Kubernetes dashboard. In fact, you can perform about 80% (or even 90% in OpenShift 4) of tasks directly from it – no need to launch command line or dealing with yaml objects – it can be actually a primary tool for managing OpenShift on a daily basis.
Which is better?
OpenShift. Sorry Kubernetes, but people (including me!) love and need fancy web console 🙂
Conclusion
Some of you may think I’m a total OpenShift fanboy, but in reality, I love working with both – OpenShift and Kubernetes. After all they make it possible to deploy and manage our containerized apps in a way that was only available for unicorns like Google. So whichever you choose you’ll get tons of features making your life easier and your journey will begin towards cloud native world.